Related Topics:
Server Build Dell Poweredge-

Which country does Huijue AI server belong to
Last month, Huawei unveiled a new AI server cluster in China's Anhui province powered by its in-house Ascend chips, not the dominant GPUs from NVIDIA. This development, alongside reports of performance gains and a growing domestic ecosystem, raises questions about whether US curbs are effectively. Huawei has started reclaiming its growth and influence in Chinese server business due to increasing demands for its AI chips. A few industry analysts reported that Huawei is. Dozens of Chinese hi-tech manufacturers - from Lenovo Group and Huawei Technologies to Inspur Group - are pushing new "all-in-one" servers that include DeepSeek 's advanced artificial intelligence (AI) models to private and public enterprises across the country, ramping up democratisation of the. TOKYO -- Huawei Technologies is steadily building up its own artificial intelligence (AI) infrastructure with homegrown chips and servers, underscoring China's progress on AI development and deployment even under U. We have launched over 220+ cloud services and 210+ solutions.
[PDF Version]
-
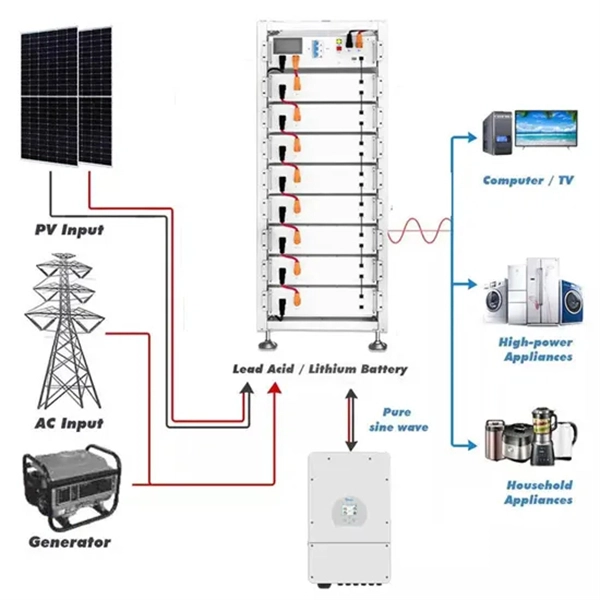
Are the different components of an AI server a large proportion of its overall performance
While traditional servers rely mostly on CPUs, AI servers lean heavily on graphics processing units (GPUs) and similar AI accelerators that are purpose-built to handle modern AI models. That's the job of an AI server—a custom-built system that keeps AI applications fast, scalable, and efficient. These servers require a combination of high-performance hardware components to process large datasets. AI, or artificial intelligence, is changing the way organizations and businesses handle data by incorporating automation of complex calculations, introducing new advanced applications, and fulfilling computational demands like never before. Key hardware components include a multi-GPU motherboard, high-performance CPU, at least 96GB RAM, effective cooling, a robust. From training complex deep learning models to performing real-time inference, the underlying server infrastructure plays a pivotal role in determining the speed, efficiency, and scalability of AI operations. A critical decision for anyone embarking on AI development or deployment is selecting the.
[PDF Version]
-

AI call not connected to server
Call reconnect(failed_only=True) to retry failed servers, or reconnect(failed_only=False) to restart all servers. I have two agents deployed in Azure AI Foundry (Switzerland North), both using a shared GPT-4. 1 model deployment: Agent 1: apples-agent Has an MCP server configured The MCP server exposes one tool: returns the number of apples in my basket Works correctly when invoked directly - returns expected. When I try to setup the connection in the playground it seems to take a long time to connect to the MCP server (if it really is, not sure) and then goes to the page to list the tools and errors out with “Unable to load tools”. MCP Server just has a single function to create a file Server Implementation @Tool(name = "Create File", description = "Create a file with the provided fileName on the file system") public String createFile(String fileName) {. Make sure you call 'connect ()' first. UserError: Server not initialized. Make sure you call 'connect ()' first. · Issue #446 · openai/openai-agents-python /agents/mcp/server.
[PDF Version]
-

P40 multi-GPU AI server
We've built a homeserver for AI experiments, featuring 96 GB of VRAM and 448 GB of RAM, with an AMD EPYC 7551P processor. We'll be testing our Tesla P40 GPUs on various LLMs and CNNs to explore their performance capabilities. We'll also share our approach to cooling these GPUs. more Audio tracks. Tesla P40 24GB for possible local AI server build. 0 16x lanes, 4GB decoding, to locally host a 8bit 6B parameter AI chatbot as a personal project. Would. This guide details the configuration steps required to properly set up multiple Tesla P40 GPUs in passthrough mode for Ollama on an Ubuntu 22. 04 VM running on a Proxmox host. Edit your VM configuration file (/etc/pve/qemu-server/YOUR_VM_ID. It runs 30B+ models that gaming GPUs under $200 can't touch. The catch: no display output, no fans, no native FP16, and you'll need a cooling mod. Pre-installed NVIDIA drivers, Linux/Windows support, and flexible CPU–Memory–GPU combinations make it ideal for AI training, inference, rendering, and scientific computing. Equipped with a substantial 24 GB of GDDR5 VRAM, this GPU is an intriguing option for those looking to run local text generation models.
[PDF Version]
-

Huawei AI Server Liquid Cooling
Huawei developed a full liquid cooling solution, reducing the power consumption by 96% and cutting the PUE from 2. This increase in power density has posed an unprecedented challenge to conventional cooling systems. To address this challenge, Huawei. Advanced AI chips are generating more heat in data centers, necessitating improved cooling solutions. Proposed techniques include circulating water through cold plates, circulating boiling liquid through cold plates. Liquid cooling is essential for AI-driven data centres, efficiently managing the extreme heat generated by high-density AI server racks. It offers up to 15% better energy efficiency and reduces cooling costs compared to traditional air-cooling systems The technology also enables higher server. This AI revolution is built on incredibly powerful computer chips. But there's a catch, a hot one. These chips, especially the GPUs that are the workhorses of AI, are generating a staggering amount of heat.
[PDF Version]
-

Current Status of AI Server Development
Dell, HPE, Lenovo, and Supermicro are riding record AI server demand, but winning enterprise customers requires more than just Nvidia chips. With GPUs standardized around Nvidia, vendors compete on AIOps, liquid cooling, and deployment services as enterprises ramp up inference in 2026. A comprehensive report by Global Market Insights Inc. The market is expected to grow from USD 167. 88 billion in 2024, at a CAGR of 34. This surge is driven by rising demand for AI applications, advancements in AI technology, cloud and edge computing expansion, and big data analytics. The AI server market is projected to reach US$245 billion in 2025 and is expected to grow to US$523 billion by 2030, driven by rising demand for Generative AI (Gen AI) tools like ChatGPT, Perplexity, and Claude, ABI Research said in a report. Enterprises increasingly deploy AI models in-house.
[PDF Version]
-

Does AI require server configuration
Server needs vary depending on the AI phase: Training: Demands the most resources (high-end GPUs, large RAM). Inference: Requires less power than training, but still needs optimized hardware. Choosing the right AI server setup for your workload is crucial to ensuring optimal performance and scalability. In this comprehensive guide, we will explore the key factors to consider when selecting an AI server setup, including understanding your AI workload requirements, determining the right. AI, or artificial intelligence, is changing the way organizations and businesses handle data by incorporating automation of complex calculations, introducing new advanced applications, and fulfilling computational demands like never before. Role: GPUs are very. A server for local AI inference should not be chosen by the most expensive graphics card, but by whether the model, working cache and parallel requests fit into video memory, and whether the system has enough CPU resources, PCIe lanes, power and cooling. For a small model and a few users, one.
[PDF Version]