Related Topics:
Lenovo Revolutionizes Real Time-

Is there a high global demand for AI servers
IDC reports the global server market reached a record $444 billion in 2025. With AI infrastructure remaining a strategic priority, IDC projects AI infrastructure spending will reach $487 billion in 2026 and surpass $1 trillion by 2029. 28 billion by 2034, at a remarkable CAGR of 27. This surge is driven by rising demand for AI applications, advancements in AI technology, cloud and edge computing expansion, and big data analytics. A comprehensive report by Global Market Insights Inc. Explosive enterprise AI adoption and proven return on. The AI Server Market is experiencing robust growth driven by technological advancements and increasing demand for efficient data processing solutions. Energy efficiency has. Soaring demand for AI-ready data centers offers many opportunities for companies and investors across the value chain. How quickly they grasp them could determine the pace at which AI is deployed.
[PDF Version]
-

Does AI require server configuration
Server needs vary depending on the AI phase: Training: Demands the most resources (high-end GPUs, large RAM). Inference: Requires less power than training, but still needs optimized hardware. Choosing the right AI server setup for your workload is crucial to ensuring optimal performance and scalability. In this comprehensive guide, we will explore the key factors to consider when selecting an AI server setup, including understanding your AI workload requirements, determining the right. AI, or artificial intelligence, is changing the way organizations and businesses handle data by incorporating automation of complex calculations, introducing new advanced applications, and fulfilling computational demands like never before. Role: GPUs are very. A server for local AI inference should not be chosen by the most expensive graphics card, but by whether the model, working cache and parallel requests fit into video memory, and whether the system has enough CPU resources, PCIe lanes, power and cooling. For a small model and a few users, one.
[PDF Version]
-

Multi-channel AI Server
In this guide, you'll learn how to architect a Multi-Channel Processing (MCP) server using FastAPI and LangChain. This setup is ideal for projects involving LLMs and AI agents, where performance, modularity, and extensibility matter. 🚀 Why FastAPI + LangChain?OpenClaw is a self-hosted gateway that connects WhatsApp, Telegram, Discord, and iMessage to AI coding agents. You run one Gateway process on your machine, and it becomes the bridge between your messaging apps and an AI assistant you control. OpenClaw installed and running. A configuration file (usually. OpenClaw's multi-agent routing lets you run a whole team of specialized AI agents — each with their own personality, memory, and skills — all from a single server. This. Our stack prioritizes performance, reliability, and scalability, serving as the foundation for teams shipping production-grade autonomous systems.
[PDF Version]
-

AI servers surge 20 times
The rapid growth of AI inference services is boosting demand for general-purpose servers, supporting both replacement and expansion efforts. 8%. North American CSPs' continued investments in AI infrastructure are expected to increase global AI server shipments by more than 28% YoY in 2026, according to the latest market research from TrendForce. The expansion in production by TSMC, SK Hynix, Samsung, and Micron has alleviated shortages in the second quarter. This article is a collaborative effort by Bhargs Srivathsan, Marc Sorel, and Pankaj Sachdeva, with Arjita Bhan, Haripreet Batra, Raman Sharma, Rishi Gupta, and Surbhi Choudhary, representing views from McKinsey's Technology, Media & Telecommunications Practice. As challenging as this could be. The global AI Servers Market is poised for significant growth, starting at USD 50. 05 Billion in 2026 and projected to reach USD 558. I need the full data tables, segment breakdown, and competitive landscape for detailed regional analysis and. A comprehensive report by Global Market Insights Inc. 6%, AWS at 16%, and Meta at 10.
[PDF Version]
-

Huawei AI Server Liquid Cooling
Huawei developed a full liquid cooling solution, reducing the power consumption by 96% and cutting the PUE from 2. This increase in power density has posed an unprecedented challenge to conventional cooling systems. To address this challenge, Huawei. Advanced AI chips are generating more heat in data centers, necessitating improved cooling solutions. Proposed techniques include circulating water through cold plates, circulating boiling liquid through cold plates. Liquid cooling is essential for AI-driven data centres, efficiently managing the extreme heat generated by high-density AI server racks. It offers up to 15% better energy efficiency and reduces cooling costs compared to traditional air-cooling systems The technology also enables higher server. This AI revolution is built on incredibly powerful computer chips. But there's a catch, a hot one. These chips, especially the GPUs that are the workhorses of AI, are generating a staggering amount of heat.
[PDF Version]
-

P40 multi-GPU AI server
We've built a homeserver for AI experiments, featuring 96 GB of VRAM and 448 GB of RAM, with an AMD EPYC 7551P processor. We'll be testing our Tesla P40 GPUs on various LLMs and CNNs to explore their performance capabilities. We'll also share our approach to cooling these GPUs. more Audio tracks. Tesla P40 24GB for possible local AI server build. 0 16x lanes, 4GB decoding, to locally host a 8bit 6B parameter AI chatbot as a personal project. Would. This guide details the configuration steps required to properly set up multiple Tesla P40 GPUs in passthrough mode for Ollama on an Ubuntu 22. 04 VM running on a Proxmox host. Edit your VM configuration file (/etc/pve/qemu-server/YOUR_VM_ID. It runs 30B+ models that gaming GPUs under $200 can't touch. The catch: no display output, no fans, no native FP16, and you'll need a cooling mod. Pre-installed NVIDIA drivers, Linux/Windows support, and flexible CPU–Memory–GPU combinations make it ideal for AI training, inference, rendering, and scientific computing. Equipped with a substantial 24 GB of GDDR5 VRAM, this GPU is an intriguing option for those looking to run local text generation models.
[PDF Version]
-
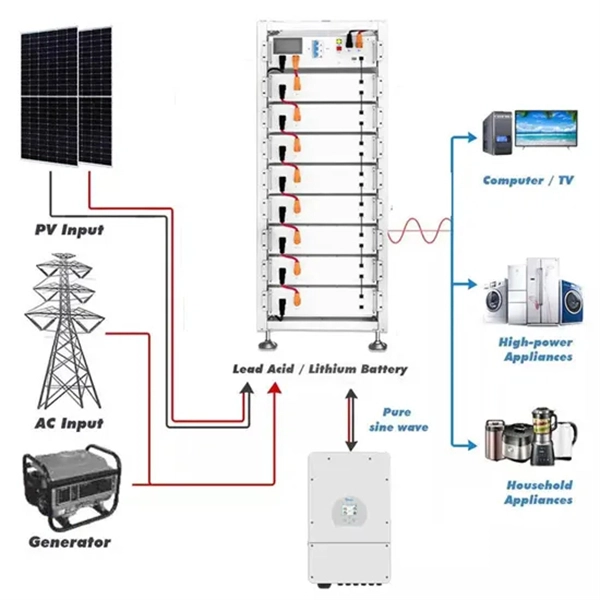
Are the different components of an AI server a large proportion of its overall performance
While traditional servers rely mostly on CPUs, AI servers lean heavily on graphics processing units (GPUs) and similar AI accelerators that are purpose-built to handle modern AI models. That's the job of an AI server—a custom-built system that keeps AI applications fast, scalable, and efficient. These servers require a combination of high-performance hardware components to process large datasets. AI, or artificial intelligence, is changing the way organizations and businesses handle data by incorporating automation of complex calculations, introducing new advanced applications, and fulfilling computational demands like never before. Key hardware components include a multi-GPU motherboard, high-performance CPU, at least 96GB RAM, effective cooling, a robust. From training complex deep learning models to performing real-time inference, the underlying server infrastructure plays a pivotal role in determining the speed, efficiency, and scalability of AI operations. A critical decision for anyone embarking on AI development or deployment is selecting the.
[PDF Version]
-

Relay protection current coordination time
The IEC standard for relay coordination recommends time grading between relays based on fault current magnitude and operating characteristics. For overcurrent protection, a minimum time margin of 0. 5 seconds is often maintained between primary and backup relays. Co-ordination procedure Correct overcurrent relay application requires knowledge of the fault current that can flow in each part of the. Selective short-circuit protection can be achieved in different ways, such as: Time-graded protection Time- and current-graded protection A straightforward way of obtaining selective protection is to use time grading. Ensure that the minimium, un-faulted load is interrupted when the protective. Overlay time-current curves (TCC) for upstream and downstream protective devices to ensure selective operation. Look for overlapping curves where multiple devices may trip simultaneously, leading to unnecessary outages.
[PDF Version]
-

KVM Switch Response Time
High-end KVM switches add negligible input lag (often <1ms) that is imperceptible in competitive play. Budget or older KVMs can introduce delays exceeding 2-3ms, hurting your reaction times. Prioritize KVMs with DisplayPort 1. The primary benefit of a KVM switch is the consolidation of hardware, which leads to saving physical space and reducing the need. Sophea Dave is a writer and gamer who covers Xtreme Gaming for Joltfly. Sophea knows the gaming industry inside out and helps readers of all levels improve their gaming experience. This is super useful for people who have more than one computer but don't want the hassle of switching between different. I use a KVM because I run both my development workstation and my main PC from the same monitor (s). I'm planning to buy the ASUS ROG Swift PG32UCDM, also for its built-in KVM, and I want to use it with my Wooting 60HE and DeathAdder V3 Pro. Has anyone tested a similar setup with this monitor's or other.
[PDF Version]